Hello!
This Notebook is associated with the ICASSP2022 submission, presenting audio outputs of the Nonnegative Tucker Decomposition (NTD) when optimizing different loss functions. In particular, the three evaluated loss functions are three special cases of the more general $\beta$-divergence:
- The Euclidean norm, $\beta = 2$,
- The Kullback-Leibler (KL) divergence, $\beta = 1$,
- The Itakura-Saito (IS) divergence, $\beta = 0$.
More details about our algorithm are to be found in the ICASSP submsission (which should be the reason of your presence on this page). Audio signals are obtained by applying the Griffin-Lim algorithm to STFT.
This notebook will present signals, showing results of:
- The Griffin-Lim algortihm itself, by recomposing the phase of the original STFT of the song, to serve as a baseline for the other estimations. This baseline condition already presents some artifacts on the reconstructed signal.
- A comparison of the decomposition results with the three different loss functions. This comparison is obtained by omparing:
- The reconstructed song itself, result of the whole decomposition,
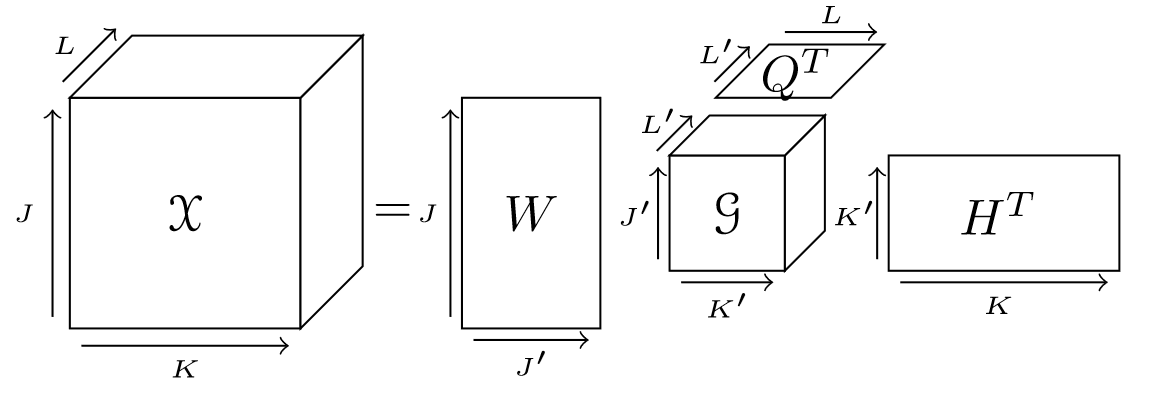
- The different patterns ($W G_{[:,:,i]} H^T$, with $i$ the pattern index), obtained by the decomposition.
Note though that signals representing songs will be limited to the first 16 bars, in order to limit the size of this HTML page.
We insist on the fact that, while audio signals are listenable, they are not of profesional musical quality either due to inaccuracies in the decomposition or due to the phase-estimation algorithm that we use (Griffin-Lim). Improving the reconstruction of these signals could constitute future work.
In the meantime, we believe that these audio examples are good examples of the potential and outputs of the NTD, and allow to qualitatively evaluate the differences between the different loss functions.
Imports¶
Let's start with importing external librairies (which are installed automatically if you used pip install, otherwise you should install them manually).